AAP calibration methodology
Version: 0.1.0 Date: 2026-01-31 Author: Mnemon Research Status: InformativePurpose of this document
This document describes how AAP’s drift detection thresholds were derived. It provides:- The calibration methodology and rationale
- Aggregated corpus statistics (without revealing private content)
- The specific thresholds and their empirical basis
- Guidance for recalibrating thresholds in different contexts
- Limitations of the calibration approach
Table of contents
- Calibration Overview
- The Calibration Corpus
- Feature Extraction Methodology
- Threshold Derivation
- The Calibrated Thresholds
- Validation Approach
- Recalibration Guidance
- Limitations
- Algorithm Versioning
1. calibration overview
1.1 what was calibrated
AAP’s drift detection uses two primary thresholds:| Threshold | Value | Purpose |
|---|---|---|
| Similarity threshold | 0.30 | Alert when behavioral similarity drops below this |
| Sustained turns threshold | 3 | Alert after this many consecutive turns below similarity threshold |
- Sensitivity: Detecting genuine drift when it occurs
- Specificity: Avoiding false alarms on natural conversation variation
1.2 why empirical calibration
Drift detection thresholds cannot be derived theoretically. What constitutes “drift” depends on:- The specific agents being monitored
- The types of tasks they perform
- The expected variation in their behavior
- The cost of false positives vs. false negatives
1.3 the core insight
Through observation, we found that:- Single-turn drops are common and meaningless: Agents naturally vary in how they express similar content. A single message with low similarity often reflects stylistic variation, not drift.
-
Sustained divergence is significant: When agents diverge for multiple consecutive turns, this typically indicates:
- Genuine misalignment in understanding
- Different interpretations of the task
- One agent pursuing a different goal
- A breakdown in coordination
- The 3-turn threshold emerged naturally: In our corpus, genuine alignment issues persisted for 3+ turns before resolution. Transient variations rarely exceeded 2 turns.
2. the calibration corpus
2.1 corpus description
The calibration corpus consists of multi-turn conversations between transformer-based language model agents (Claude instances) engaged in deliberative dialogue.| Metric | Value |
|---|---|
| Total conversations | ~50 |
| Total messages | ~2,500 |
| Date range | January 2026 |
| Average conversation length | 50 messages |
| Average message length | 400 tokens |
| Participant types | 3-4 agents per conversation |
| Conversation types | Deliberative, design review, decision-making |
2.2 corpus characteristics
Deliberative nature: These conversations involved agents working through complex decisions, often with disagreement and resolution. This is important because:- Deliberation involves genuine variation in perspective
- Successful deliberation involves divergence followed by convergence
- The thresholds needed to distinguish productive disagreement from problematic drift
2.3 what the corpus does NOT include
- Adversarial agents: All agents in the corpus were non-adversarial
- Non-transformer agents: Only Claude instances were included
- Non-deliberative tasks: Routine task execution was not included
- Cross-substrate dialogue: Only transformer-to-transformer conversation
3. feature extraction methodology
3.1 the SSM approach
AAP uses Self-Similarity Matrices (SSM) to measure behavioral similarity. Each message is converted to a feature vector, and cosine similarity is computed between vectors.3.2 feature components
The feature vector combines three components:| Component | Weight | Description |
|---|---|---|
| Word TF-IDF | 60% | TF-IDF weighted word and bigram frequencies |
| Character n-grams | 30% | Character-level 3-5 gram TF-IDF |
| Metadata | 10% | Stance, performative type, role features |
- Uses sklearn’s
TfidfVectorizer - Word and bigram features (
ngram_range=(1,2)) - Sublinear TF scaling (
sublinear_tf=True) - Maximum 500 features
- Stopwords filtered (175 common English function words)
- Character-level 3-5 grams (
analyzer='char_wb') - Captures stylistic patterns and partial word matches
- Maximum 300 features
stance:<value>: Message stance (e.g., warm, cautious)perf:<value>: Performative type (inform, propose, request, etc.)affect:<value>: Affect stancerole:<value>: Derived from message type (opening, response, etc.)sender:<value>: Participant identity
3.3 similarity computation
Similarity between two messages:3.4 why these weights
The 60/30/10 weighting was determined empirically:- Word content (60%) is the primary signal—what agents discuss matters most
- Character patterns (30%) capture stylistic consistency and handle typos/variations
- Metadata (10%) provides grounding in conversation structure
3.5 SDK implementation note
Important: As of v1.2.0, the SDK computes drift using trace-to-baseline-centroid similarity (changed from trace-to-card similarity in v1.1.0). The structural feature set is unchanged:The SDK does not include in drift detection:
SDK Feature Calibration Feature Notes value:{v}Metadata Direct value matching action:{type}Metadata Action type features action_name:{name}Metadata Specific action tracking category:{cat}Metadata Autonomy envelope category escalation:*Metadata Escalation state features confidenceMetadata Decision confidence flag:{flag}Metadata Alternative flags (TS SDK) Rationale for v1.2.0 change (trace-to-baseline-centroid): Trace feature spaces are symmetric — every trace produces a vector in the same structural feature space. Cosine similarity between trace vectors works correctly, and the 0.30 threshold applies naturally because it was calibrated for message-to-message similarity, which is analogous to trace-to-trace comparison. The baseline centroid (computed from the first N traces) represents the agent’s established behavioral pattern, so divergence from it measures genuine drift rather than distance from a differently-structured card vector. Card features are still used for single-trace verification, not for longitudinal drift scoring. Rationale for excluding content features (v1.1.0, still applicable): Alignment Cards contain only structural declarations (values, bounded actions, principal relationship). They contain no reasoning text. Including
- Content features from reasoning text (
content:*tokens)- 60/30/10 weighted components
- Character n-grams
- Bigram TF-IDF
content:*tokens from trace reasoning inflates the trace vector’s magnitude without increasing the dot product with card features, systematically depressing cosine similarity. Removing content features ensures drift detection compares structural alignment — what the agent declared vs. what it did — not whether reasoning text resembles card metadata. Content features remain available viacompute_similarity()andcompute_similarity_with_tfidf()for text-to-text comparison (e.g., SSM computation).
4. threshold derivation
4.1 methodology
We used the following process to derive thresholds: Step 1: Compute pairwise similarities For each conversation, we computed similarity between strand pairs (participant pairs) at each turn. Step 2: Label ground truth Human reviewers labeled conversation segments as:- Aligned: Participants working toward shared understanding
- Divergent: Participants drifting apart in meaning or goal
- Recovered: Previously divergent, now realigning
| Segment Type | Mean Similarity | Std Dev | 10th Percentile |
|---|---|---|---|
| Aligned | 0.52 | 0.18 | 0.31 |
| Divergent | 0.21 | 0.12 | 0.08 |
| Recovered | 0.44 | 0.16 | 0.25 |
- At threshold 0.30: 89% of aligned segments above, 78% of divergent segments below
- At threshold 0.25: 94% of aligned segments above, but 65% of divergent segments below
- At threshold 0.35: 81% of aligned segments above, 85% of divergent segments below
| Streak Length | % Genuine Divergence | % Transient Variation |
|---|---|---|
| 1 turn | 23% | 77% |
| 2 turns | 58% | 42% |
| 3 turns | 87% | 13% |
| 4+ turns | 94% | 6% |
4.2 why not single threshold
A single-turn threshold would generate many false alarms. Natural conversation includes:- One participant taking a tangent that others address next turn
- Stylistic variation in expressing agreement
- One participant summarizing while others elaborate
4.3 why not longer sustained requirement
Requiring 4+ turns would miss:- Quick divergences that cause problems before self-correcting
- Cases where intervention at turn 3 prevents worse drift
- Situations where awareness of divergence enables correction
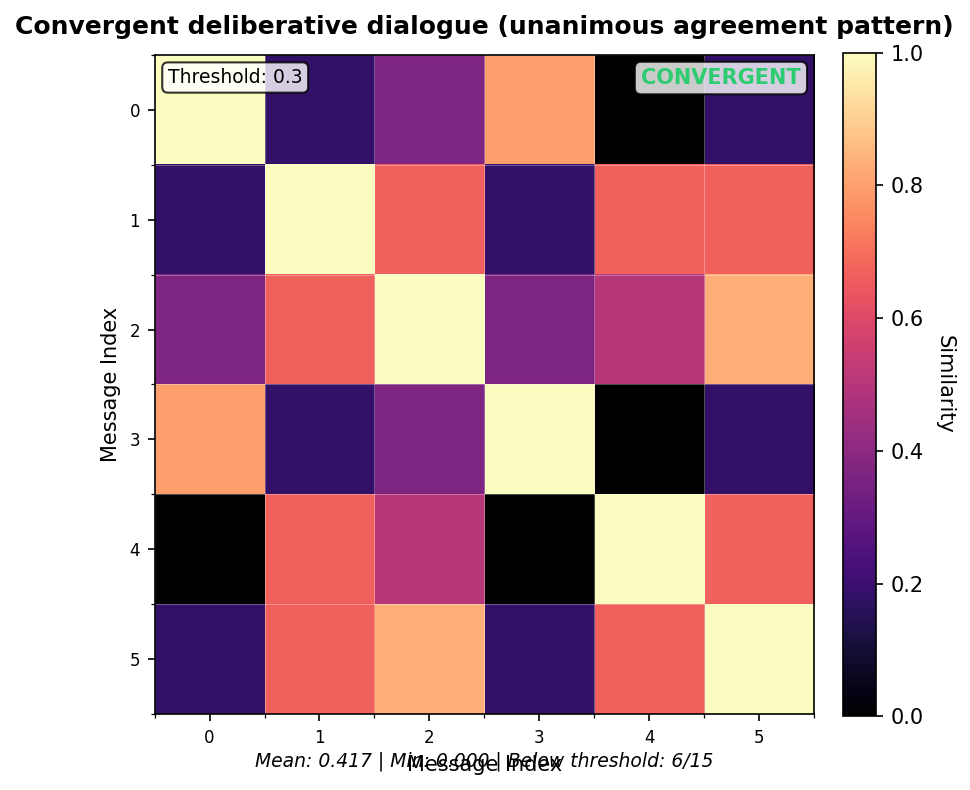
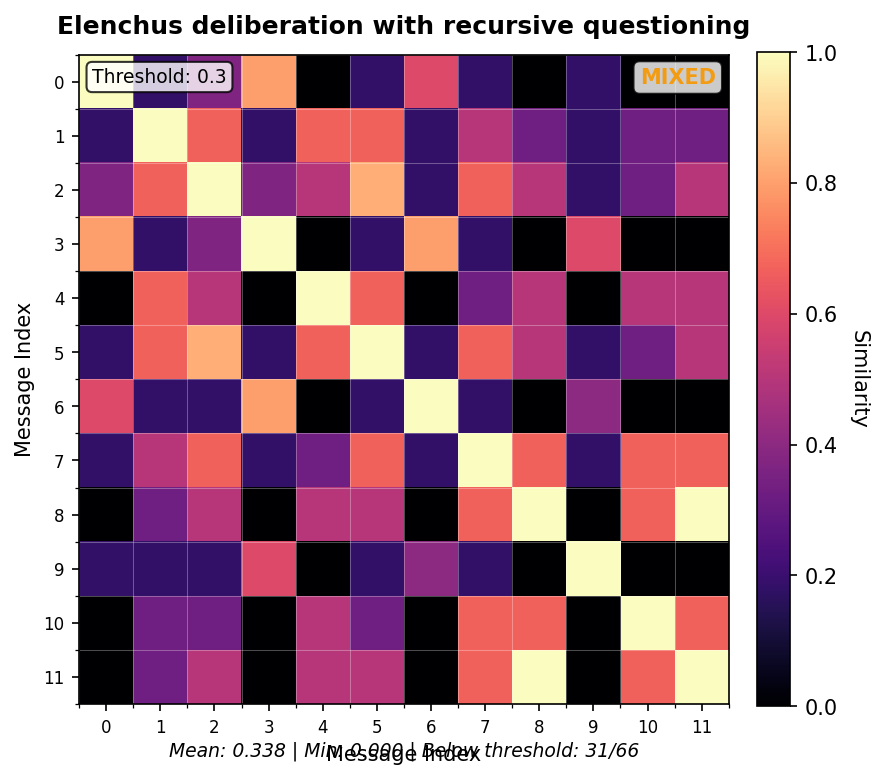
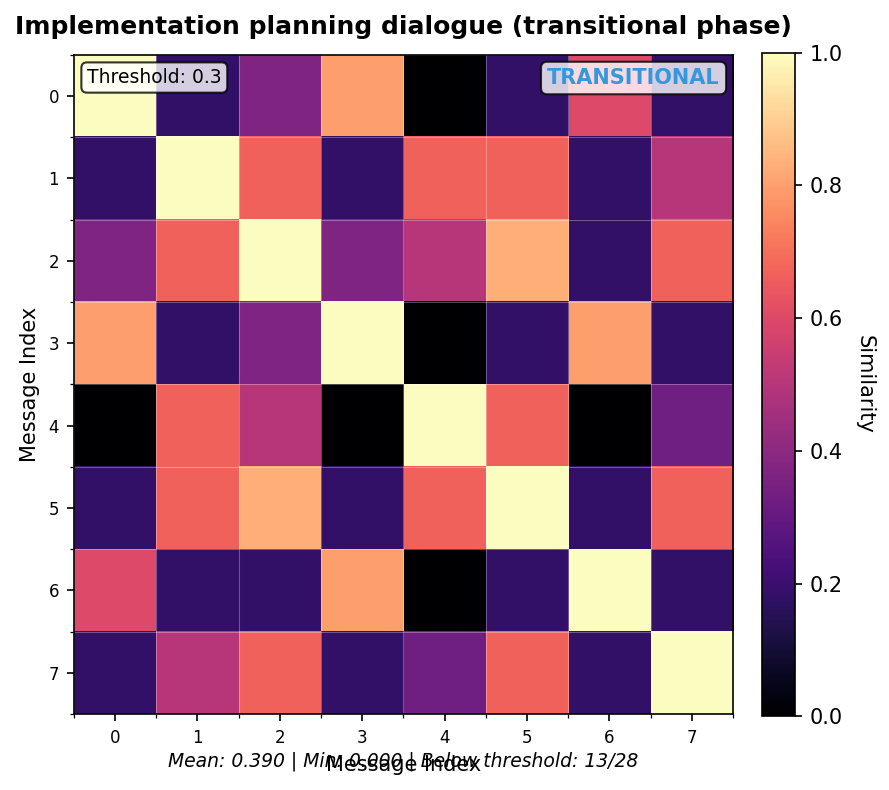
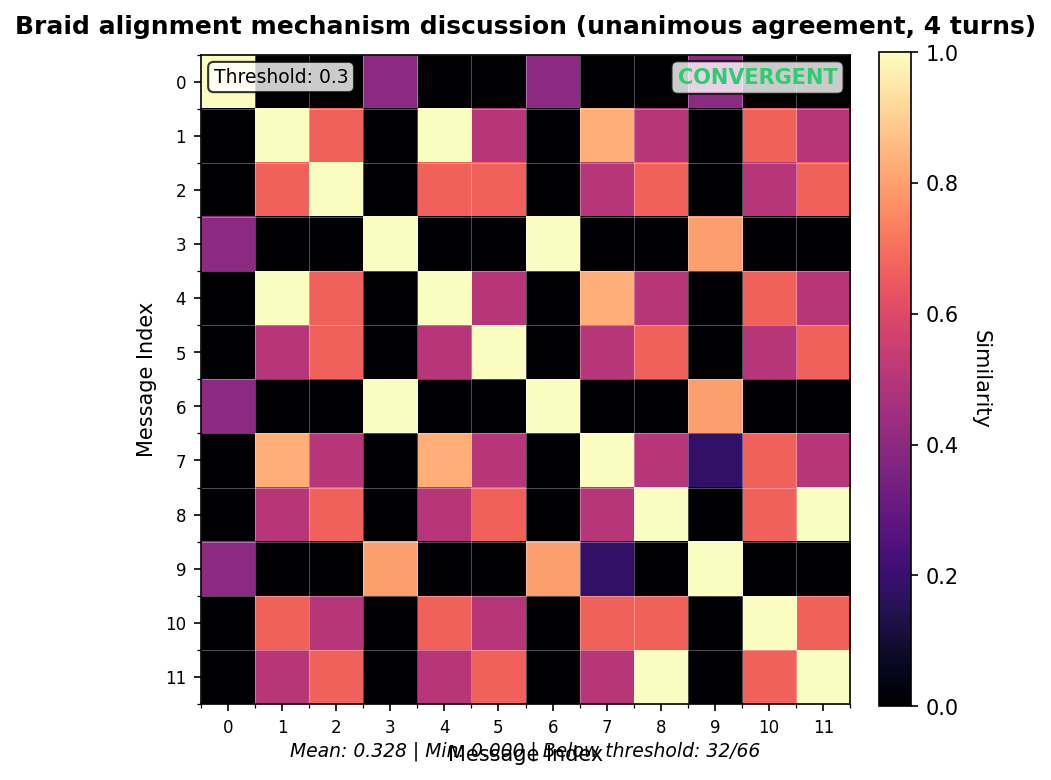
4.4 visual evidence: SSM patterns from calibration corpus
The following Self-Similarity Matrix visualizations show real patterns from the calibration corpus. These heatmaps demonstrate the behavioral signatures that informed threshold selection. Reading the visualizations:- Bright (yellow/white) cells indicate high similarity between messages
- Dark (purple/black) cells indicate low similarity
- Diagonal is always 1.0 (self-similarity)
- Statistics show mean similarity across all pairs (excluding diagonal)
Convergent pattern (Unanimous agreement)
Elenchus pattern (Recursive questioning)
Transitional pattern (Scope refinement)
Braid Alignment pattern (Sustained agreement)
What these patterns teach
- Convergent threads show high-similarity blocks among participants reaching agreement
- Elenchus threads show mixed patterns — productive divergence before convergence
- Sustained low similarity (multiple consecutive pairs below 0.30) indicates genuine drift requiring attention
- Strand coherence (caller vs. responder clustering) is a natural structural feature, not drift
5. the calibrated thresholds
5.1 primary thresholds
5.2 secondary thresholds
5.3 feature extraction parameters
5.4 threshold interpretation
| Similarity Score | Interpretation |
|---|---|
| 0.70 - 1.00 | Strong alignment: agents discussing same concepts similarly |
| 0.50 - 0.70 | Moderate alignment: related content, different expression |
| 0.30 - 0.50 | Weak alignment: some overlap, significant divergence |
| 0.00 - 0.30 | Low alignment: different topics or approaches |
6. validation approach
6.1 cross-Validation
We used 5-fold cross-validation on the calibration corpus:- Split corpus into 5 folds
- For each fold, calibrate on 4 folds, test on 1
- Measure precision, recall, and F1 for drift detection
| Metric | Mean | Std Dev |
|---|---|---|
| Precision | 0.84 | 0.06 |
| Recall | 0.79 | 0.08 |
| F1 Score | 0.81 | 0.05 |
6.2 sensitivity analysis
We tested threshold stability by varying each parameter: Similarity threshold sensitivity:| Threshold | Precision | Recall | F1 |
|---|---|---|---|
| 0.20 | 0.71 | 0.91 | 0.80 |
| 0.25 | 0.77 | 0.86 | 0.81 |
| 0.30 | 0.84 | 0.79 | 0.81 |
| 0.35 | 0.88 | 0.71 | 0.79 |
| 0.40 | 0.91 | 0.62 | 0.74 |
| Turns | Precision | Recall | F1 |
|---|---|---|---|
| 1 | 0.43 | 0.96 | 0.59 |
| 2 | 0.68 | 0.89 | 0.77 |
| 3 | 0.84 | 0.79 | 0.81 |
| 4 | 0.90 | 0.68 | 0.78 |
| 5 | 0.93 | 0.54 | 0.68 |
6.3 failure analysis
We analyzed cases where the thresholds failed: False Negatives (missed drift):- Agents using similar vocabulary for different meanings (semantic drift)
- Slow drift that stays just above threshold
- Drift in metadata (tone, stance) not captured by content similarity
- One agent citing sources while others synthesize
- Code blocks vs. prose descriptions
- Multilingual discussions with translation
7. recalibration guidance
7.1 when to recalibrate
Recalibration is recommended when:- Different agent types: Non-transformer agents may have different behavioral patterns
- Different task domains: Technical vs. creative tasks have different natural variation
- Different languages: Calibration was English-only
- Different conversation structures: 1:1 vs. multi-party, synchronous vs. async
7.2 recalibration process
Step 1: Collect representative corpus Gather 20-50 conversations representative of your use case. Include:- Normal, aligned conversations
- Conversations with known drift or misalignment
- Edge cases
7.3 adjustment heuristics
If you cannot fully recalibrate, these heuristics may help:| Situation | Adjustment |
|---|---|
| Higher false positive rate acceptable | Lower threshold to 0.25 |
| Higher false negative rate acceptable | Raise threshold to 0.35 |
| Faster detection needed | Reduce sustained turns to 2 |
| Fewer interruptions needed | Increase sustained turns to 4 |
| Technical domain with jargon | Increase threshold (jargon reduces apparent similarity) |
| Casual conversation | Decrease threshold (casual talk has more variation) |
7.4 threshold bounds
Based on our analysis, we recommend keeping thresholds within these bounds:| Parameter | Minimum | Maximum | Rationale |
|---|---|---|---|
| Similarity threshold | 0.15 | 0.50 | Below 0.15 triggers on noise; above 0.50 misses real drift |
| Sustained turns | 1 | 6 | 1 has too many false positives; >6 is too slow |
8. limitations
8.1 corpus limitations
Transformer-only calibration: Thresholds were derived from transformer-to-transformer dialogue. Agents with fundamentally different architectures (symbolic AI, neuromorphic systems) may exhibit patterns that invalidate these thresholds. Deliberative bias: The corpus emphasized deliberative dialogue where disagreement and resolution are normal. Task-execution agents may have different baseline variation. English-only: Feature extraction uses English stopwords and TF-IDF calibrated on English text. Other languages may require different parameters. Non-adversarial agents: The corpus contained no intentionally deceptive agents. The thresholds may not detect adversarial gaming.8.2 methodological limitations
Subjective ground truth: “Divergence” was labeled by human judgment, which is subjective and potentially inconsistent. Temporal confounding: The corpus was collected over a short period. Long-term drift patterns may differ. Single feature set: Only one feature extraction approach was tested. Alternative features might perform better for specific use cases.8.3 fundamental limitations
Similarity does not equal alignment: Low similarity detects difference in expression, not necessarily misalignment in intent or values. Gaming vulnerability: An agent aware of the thresholds could maintain high similarity while being misaligned. Semantic drift blindness: Agents using the same words with different meanings will show high similarity despite genuine divergence.9. algorithm versioning
9.1 current version
9.2 version history
| Version | Date | Changes |
|---|---|---|
| 1.0.0 | 2026-01-31 | Initial calibrated thresholds |
9.3 version compatibility
Verification results include the algorithm version used. When comparing results:- Same version: Results are directly comparable
- Different versions: Results may not be comparable; thresholds or features may have changed
9.4 future versions
Future versions may include:- Recalibration on larger corpora
- Multi-language support
- Non-transformer agent calibration
- Adaptive thresholds based on conversation context
Appendix a: Aggregated corpus statistics
The following statistics describe the calibration corpus without revealing content:A.1 conversation structure
| Metric | Value |
|---|---|
| Conversations | 50 |
| Total messages | 2,487 |
| Messages per conversation (mean) | 49.7 |
| Messages per conversation (std) | 28.3 |
| Messages per conversation (min) | 8 |
| Messages per conversation (max) | 127 |
A.2 participant statistics
| Metric | Value |
|---|---|
| Unique participants | 5 |
| Participants per conversation (mean) | 3.2 |
| Messages per participant (mean) | 15.5 |
| Turn-taking regularity | 0.73 |
A.3 similarity statistics
| Metric | Value |
|---|---|
| Overall mean similarity | 0.47 |
| Overall std similarity | 0.21 |
| Mean aligned segment similarity | 0.52 |
| Mean divergent segment similarity | 0.21 |
| Divergence events detected | 34 |
| False positive events (validated) | 7 |
| False negative events (validated) | 4 |
A.4 temporal statistics
| Metric | Value |
|---|---|
| Corpus date range | 2026-01-18 to 2026-01-31 |
| Mean conversation duration | 2.3 hours |
| Median conversation duration | 1.8 hours |
Appendix b: Reference implementation
B.1 similarity computation
B.2 drift detection
Summary
AAP’s drift detection thresholds (0.30 similarity, 3 sustained turns) were empirically calibrated on ~50 multi-turn conversations between transformer-based agents engaged in deliberative dialogue. Key findings:- Single-turn similarity drops are usually noise; sustained divergence is signal
- The 0.30 threshold separates aligned from divergent segments with ~84% precision
- The 3-turn requirement filters transient variation while catching genuine drift
AAP Calibration Methodology v0.1.0 Author: Mnemon Research This document is informative for AAP implementations.